Video Models Reason Early: Exploiting Plan Commitment for Maze Solving
Princeton University
Video generation models have demonstrated emergent reasoning capabilities like solving mazes, puzzles, and physical reasoning tasks without task-specific training. Yet despite growing interest, we lack a basic understanding of how such reasoning emerges during generation and how reliably we can elicit it. We study the internal planning dynamics of video models using maze-solving as a controlled testbed. We discover early plan commitment: video diffusion models commit to a high-level motion plan within the first few denoising steps, after which further denoising alters visual details but not the underlying trajectory. We exploit this to build ChEaP (Chaining with Early Planning), improving accuracy from 7% to 67% on long mazes and by 2.5× overall on hard tasks.
Given just an image of a maze and a text prompt (hover to see!), off-the-shelf video diffusion models can successfully generate solutions to complex mazes across a range of diverse visual settings [1].
But success is unreliable. Most random seeds produce failed trajectories, and performance degrades rapidly with maze complexity. Standard best-of-N sampling helps, but wastes massive compute fully denoising every candidate. Can we understand how these models reason internally and use that to elicit better performance?
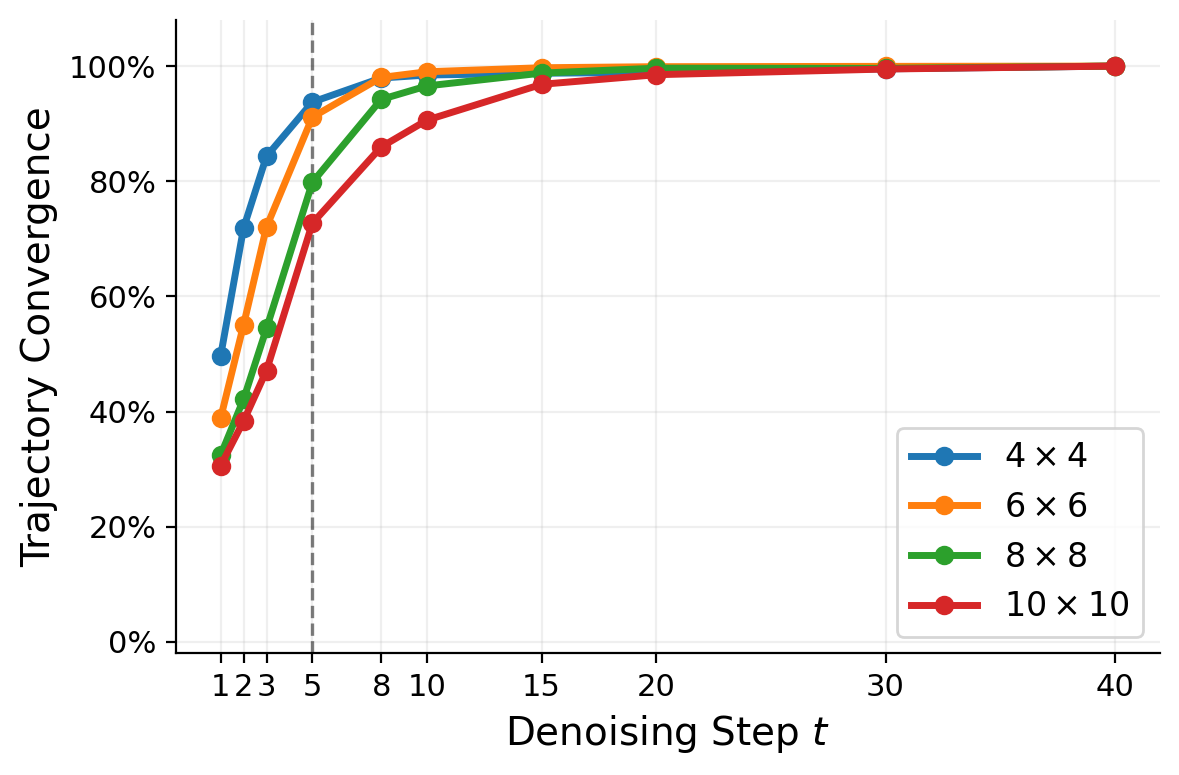
By decoding intermediate predictions during denoising, we discover that the model's motion trajectory is already committed within the first few steps. Later steps refine visual fidelity but almost never change the underlying route.
The plot on the left measures how similar the trajectory at each intermediate step is to the final output. On size 4 mazes, by step 5 of 40, trajectories are 93% converged—the route is essentially decided, and the remaining 35 steps just refine rendering quality. This holds across all maze sizes.
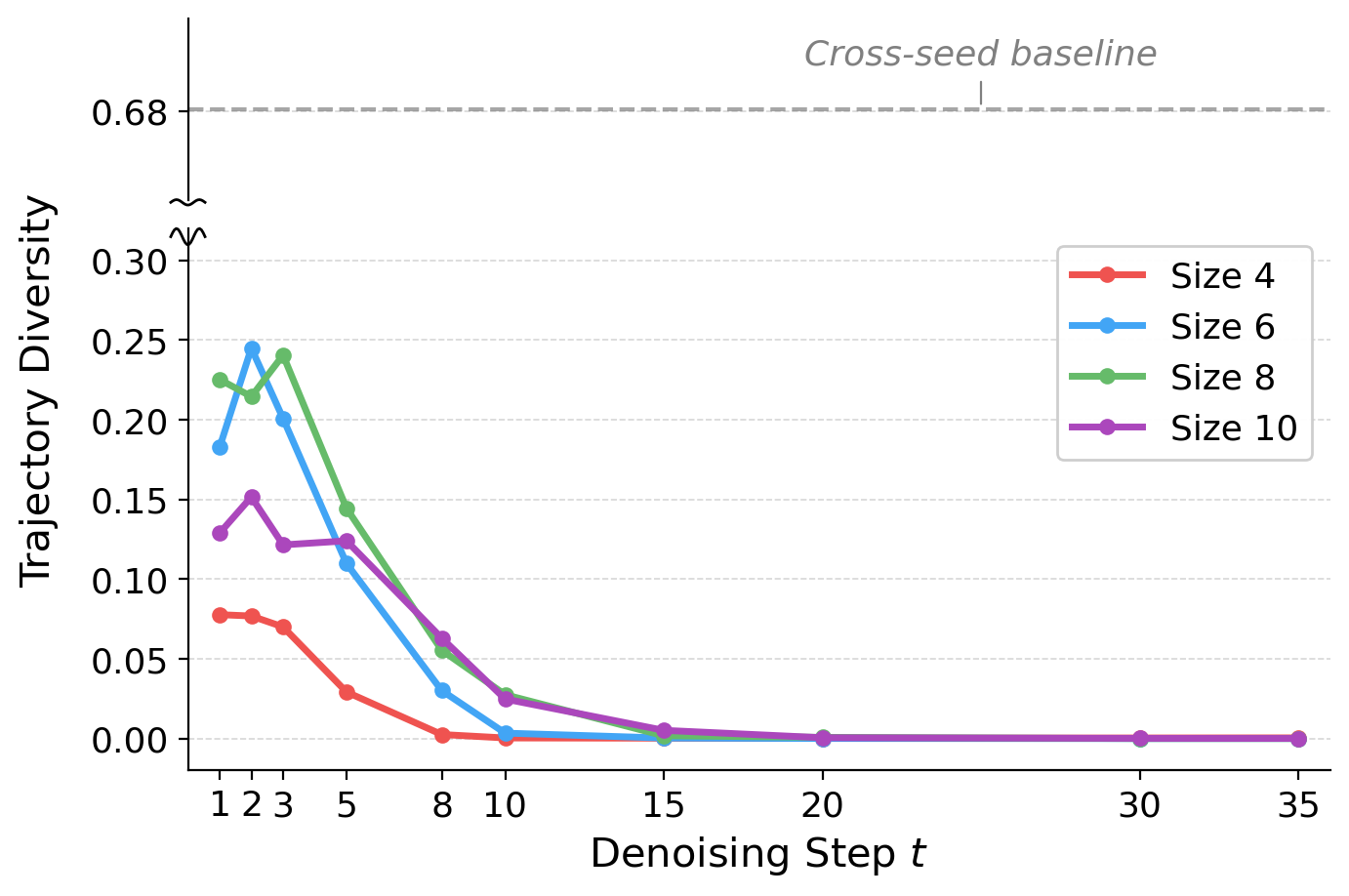
A natural follow-up: can we get diverse trajectories by refining the same seed? Refinement, i.e., re-noising an intermediate prediction and continuing denoising, is a common technique for sample diversity in flow matching. We find it produces at most 25% trajectory diversity, compared to 68% between entirely different seeds (dashed line). The trajectory is encoded in the initial noise, and refinement cannot change it.
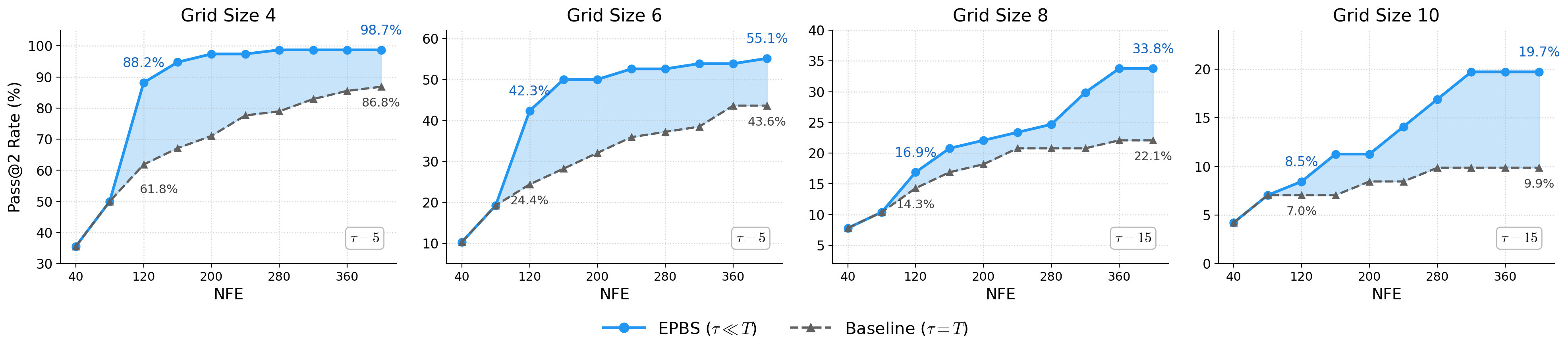
This insight motivates Early Planning Beam Search (EPBS): instead of fully denoising every seed, we partially denoise a large pool of candidates for just a few steps, decode their early trajectory plans, and score them with a lightweight verifier. Only the top-K candidates are fully denoised—the rest are discarded, saving the vast majority of compute. Under a fixed budget of function evaluations, EPBS screens far more candidate trajectories than standard best-of-N: for example, 73 candidates vs. 10 at 400 NFEs.
Different noise seeds produce strikingly different motion plans on the same maze. Failed paths appear as gray silhouettes; the successful trajectory in vivid color.
Each video above visualizes decoded early predictions from multiple noise seeds on the same maze. This is exactly what EPBS does at inference time: it reveals early trajectory plans and uses a lightweight verifier to promote the best one. Only the top-scoring candidates are fully denoised—the rest are discarded after just a few steps.
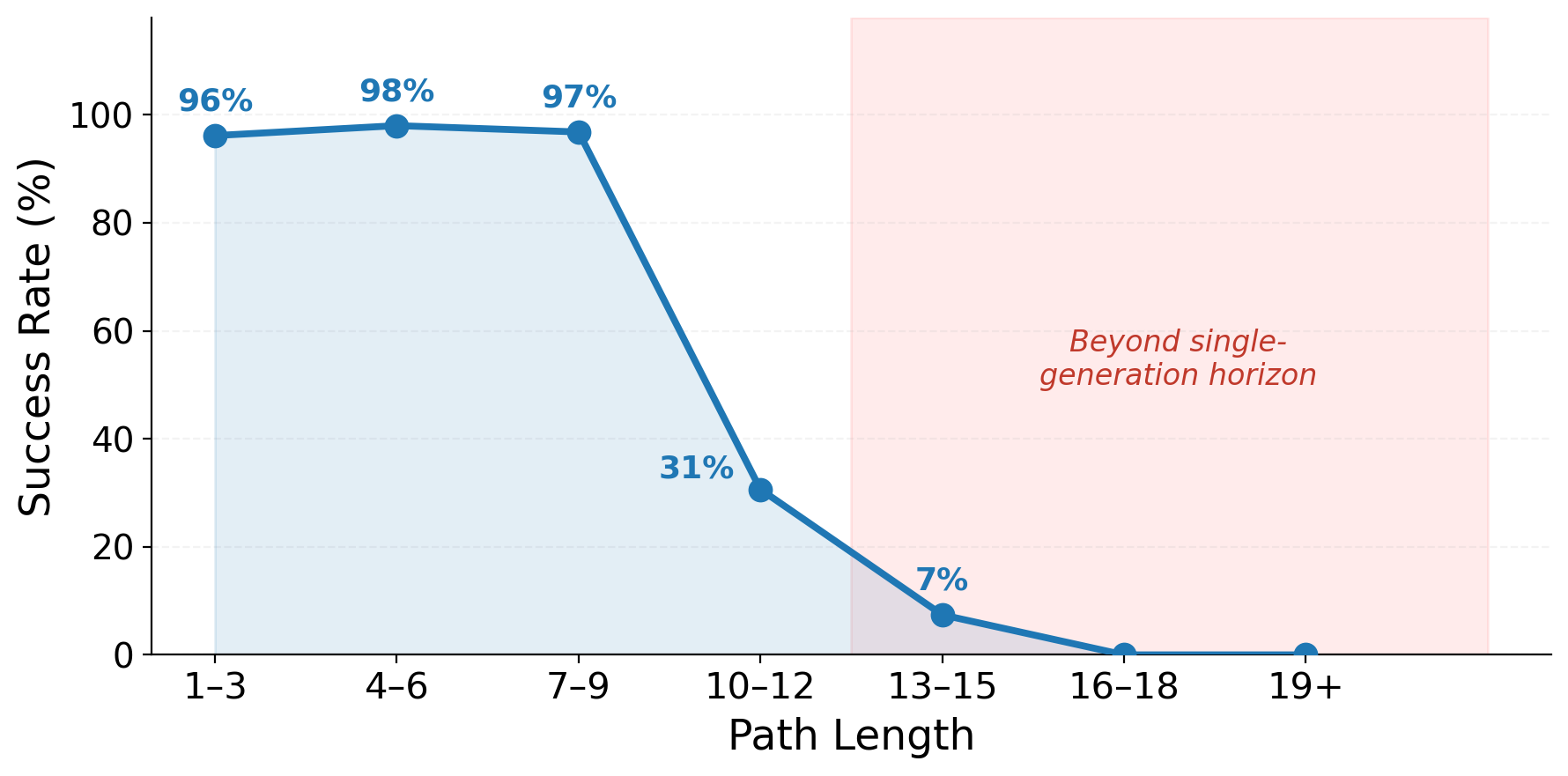
Path length—not obstacle density—is the dominant predictor of difficulty. Models reliably solve short paths but face a sharp cliff beyond 10–12 steps.
The 8×8 maze on the left has a short 3-move solution and is solved cleanly. The 6×6 maze on the right requires 10 moves—exceeding what the model can fit in a single generation. Rather than producing a valid partial trajectory, it “cheats” by moving the gift closer. This motivates decomposing long-horizon tasks into shorter sub-problems.
When a maze exceeds the model's horizon, we chain sequential generations—each picking up where the last left off. Together with EPBS, this forms ChEaP (Chaining with Early Planning).
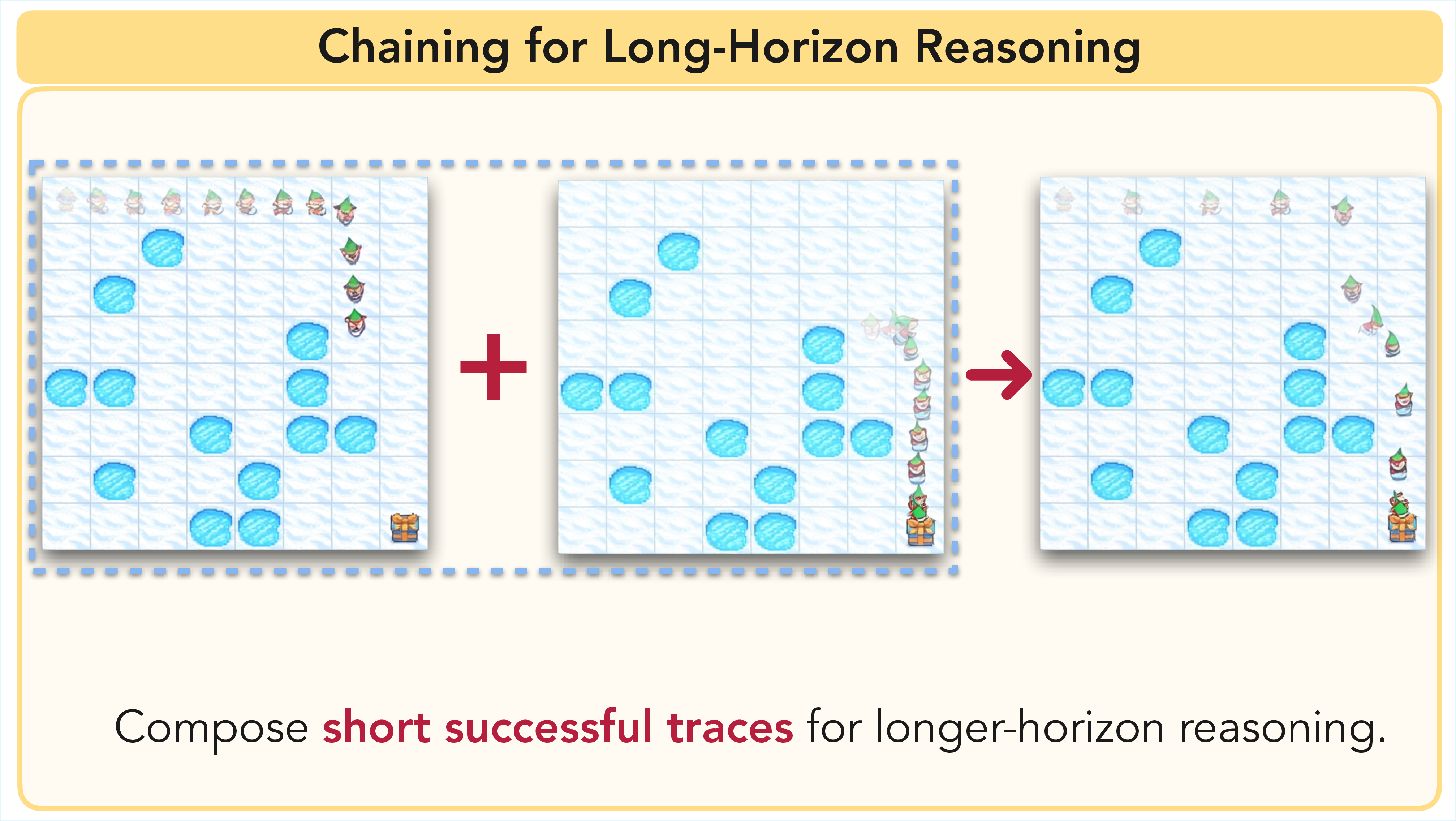
After each generation, we extract the agent's furthest valid position and use that frame as the next starting condition. On mazes with path lengths of 10–13, chaining boosts accuracy from 7% to 67%, demonstrating that the model possesses strong local planning ability that was previously hidden by the generation length bottleneck.
Successes, diverse trajectories, and failure cases across Frozen Lake and VR-Bench.
Successes
Trajectory Exploration
VR-Bench
Failure Cases
- Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. "Video Models are Zero-Shot Learners and Reasoners." arXiv preprint arXiv:2509.20328, 2025. arXiv
@misc{newman2026videomodelsreasonearly,
title={Video Models Reason Early: Exploiting Plan Commitment for Maze Solving},
author={Kaleb Newman and Tyler Zhu and Olga Russakovsky},
year={2026},
eprint={2603.30043},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.30043},
}